graph TD
OpenFisca["OpenFisca France"] -->|Extract| Param["Parameters in CSV"]
Law["DILA OpenData<br/>(LegiFrance)"] --> Trico["Tricoteuses"]
Trico --> LegiDB["LegiDB SQL"]
Param -->|Filter| Text["Create a prompt with the legal texts<br/>and the description of the parameters"]
LegiDB -->|Extract| Text
Text --> LLM["LLM<br/>to extract the value"]
LLM --> Value["Retrieve the parameter value"]
Value --> LLM1["LLM<br/>to extract the application date"]
LLM1 --> LLM2["LLM<br/>to reformulate the description"]
LLM2 --> maj["Update the parameter<br/>YAML file"]
maj --> pr["Generate the PR text"]
maj --> of_file["Updated YAML file"]
style LLM fill:#f9f,stroke:#333,stroke-width:2px
style LLM1 fill:#f9f,stroke:#333,stroke-width:2px
style LLM2 fill:#f9f,stroke:#333,stroke-width:2px
style Law fill:#cfc,stroke:#333,stroke-width:2px
style LegiDB fill:#cfc,stroke:#333,stroke-width:2px
style of_file fill:#cfc,stroke:#333,stroke-width:2px
style Param fill:#cfc,stroke:#333,stroke-width:2px
style Trico fill:#ffc,stroke:#333,stroke-width:2px
style OpenFisca fill:#ffc,stroke:#333,stroke-width:2px
Using AI to update OpenFisca parameters
A more recent article of this topic is available: Automating the Rules as Code Process with AI: Lessons from LexImpact.
Introduction
LexImpact has been a service of the French National Assembly since 2020, attached to the Control and Evaluation Department, specializing in costing and data management. The main product of the project is a socio-fiscal simulator which is based on OpenFisca, a free and open-source engine to write rules as code.
LexImpact serves as an interface for OpenFisca, allowing any citizen to interact with the OpenFisca simulator and visualize the results of calculations. The platform LexImpact, in addition to the calculation results, displays parameter values, dates, legal references, and update status. The large volume of parameters makes manual updates tedious, which has motivated the exploration of LLM-assisted automation.
The project aims to automate the retrieval and updating of fiscal parameters used in OpenFisca, a microsimulation software. The main objective is to start from an OpenFisca identifier, such as marche_travail.salaire_minimum.smic.smic_b_horaire for the hourly minimum wage, and automatically extract relevant information, such as:
- The parameter description: Smic brut (horaire)
- Its current value: 11.65€
- Start date of the value: January 1, 2024
- The corresponding legal reference: Décret du 20/12/2023
This process presents several challenges:
- Handling cases where legal references are missing or imprecise
- Updating parameter history
- Processing long and complex legal texts
- Need for a language model proficient in French and particularly in legal vocabulary
- Converting textual values to numerical format
To address these challenges, the project combines deterministic methods with the use of large language models (LLMs). The approach has evolved over time:
- June 2023: First trials with open-source language models, with limited results (about 5% success)
- July-August 2023: Attempts at fine-tuning and using models to verify existing values
- April 2024: Implementation of a read/write system for OpenFisca parameters and integration of a database of legislative texts
- July 2024: Implementation of research agents based on advanced LLMs (such as GPT-4) to find missing references, with promising results
The project ultimately aims to create a robust and efficient system to keep thousands of OpenFisca fiscal parameters up-to-date, while exploring the possibilities offered by artificial intelligence in the legal and administrative fields.
The problem
In the screenshot of the LexImpact simulator below, concerning the CSG (General Social Contribution), we can see on the left the parameters of this device:
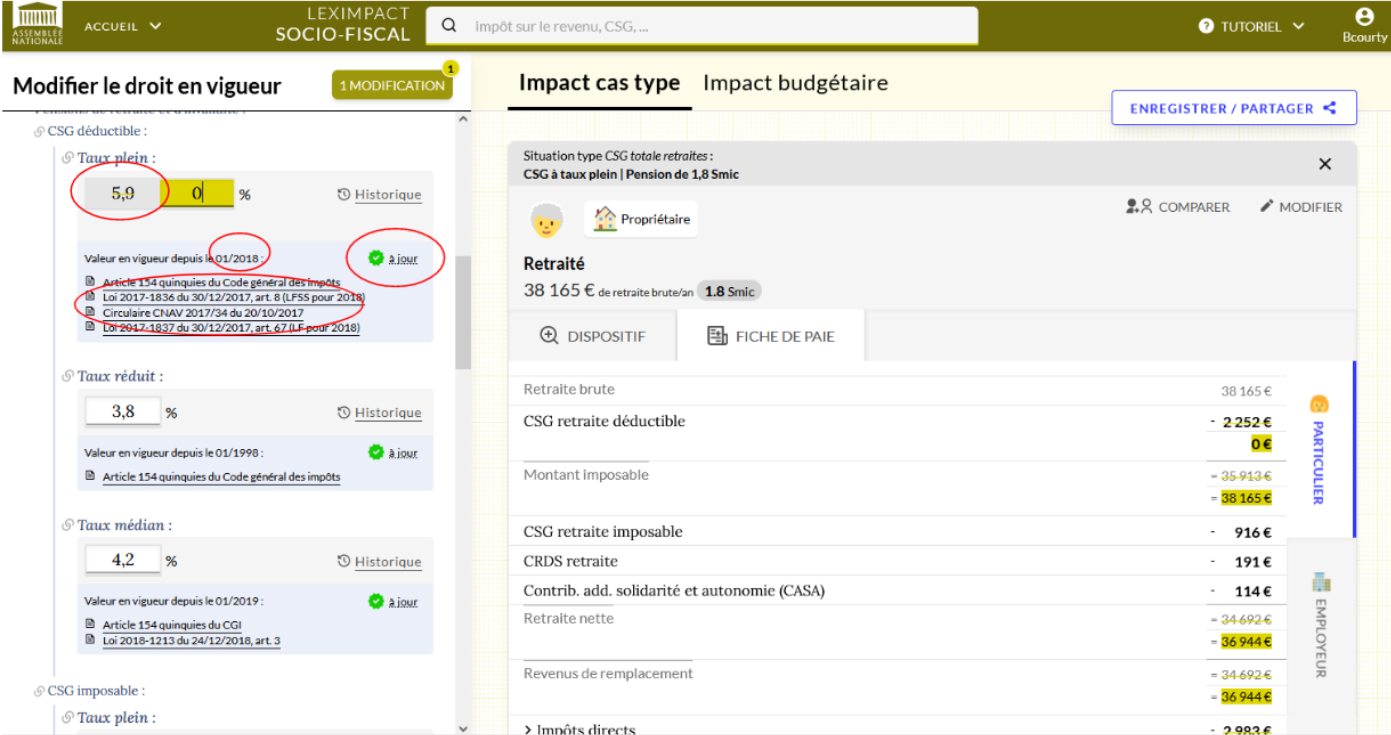
In red are the elements that require regular updates:
- The value: 5.9%
- The date of the last value change: January 2018
- The fact that the value is indeed the currently effective value, indicated by “up to date”. This is an important element for simulator users because a parameter may not have changed for years. This mention indicates that it has nevertheless been verified within the last year.
- The list of legal references justifying the parameter value. Here, Article 67 of the Finance Act for 2018 modified Article 154 quinquies of the General Tax Code.
The simulator also allows access to the parameter value history, with change dates and corresponding values.
The objective is therefore to keep this information up to date and to enrich it. Indeed, sometimes the legal reference is missing or the history is incomplete.
Use of LLMs
The simplest approach is to query an LLM by asking the following question: “What is the hourly SMIC value in August 2024?”
Here’s the response from Claude 3.5 Sonnet: “As of January 1, 2024, the gross hourly SMIC was set at 11.65 euros.”
This is accurate, but for more specific questions like “What is the value of the ‘Median rate’ for the ‘Deductible CSG rate applied to the pension base’?”
The answer is not systematically correct. For example, GPT-4o responds The value of the “Median rate” for the “Deductible CSG rate applied to the pension base” is 5.9%. whereas this is the value of the full rate and not the median rate.
Therefore, we need to assist the model by providing the reference text and explanations of what we expect from it:
You are a legal expert working at the National Assembly. Your job is to populate and update a database necessary for fiscal and social simulations. To do this, you must take the regulatory texts in which the up-to-date information is provided, and precisely extract the specific information you need.
Note that percentages are expressed in mathematical form, so a value of 25% in the legal text will be noted as 0.25 in our system. If you don’t find the answer in the text, you should look for an approximate match. If there really isn’t one, you should say so and not try to provide another one.
Before answering, verify that the answer is indeed in the indicated text. The language used is legal, you need to think step by step as understanding is sometimes difficult.
For example, the phrase “The deduction to be made for professional expenses is calculated on a flat-rate basis according to gross income, after deduction of contributions, contributions and interest mentioned in 1° to 2° ter; it is fixed at 10% of the amount of this income.” means that a deduction of 0.1 * gross income is made before calculating the amount of tax. Use the point as a decimal separator and no thousand separator. If the value is in letters, it must be put in numbers, for example fifty-six becomes 56. A “half-share” becomes 0.5. The answer should always be in JSON format, for example: { “value”: 56, } If you don’t have the answer, indicate null.
In the following text, what is the value of ‘Median rate of deductible general social contribution (CSG) on retirement and disability pensions’?
“““I. – For the determination of the tax bases for income tax, the contribution provided for in Article L. 136-1 of the Social Security Code for employment and replacement income or that relating to the income mentioned in 3° of I of Article L. 136-7 of the aforementioned code is, up to 6.8 points or, for the income mentioned in II of Article L. 136-8 of the same code, up to 3.8 points when it is levied at the rate of 3.8% or 6.2%, up to 4.2 points when it is levied at the rate of 6.6% and up to 5.9 points when it is levied at the rate of 8.3%, admitted as a deduction from the gross amount of sums paid and benefits in kind or in cash granted, or from the taxable profit, in respect of which the contribution was paid. The contribution due on the benefit mentioned in I of Article 80 bis as well as on the benefit mentioned in I of Article 80 quaterdecies when the latter is taxed on income tax according to the common law rules of salaries and wages is admitted as a deduction from the taxable income of the year of its payment.”“”
The response from GPT-4o-mini is then:
The text provides the rates and associated points for the deductible general social contribution (CSG) on retirement and disability pensions, but it does not directly indicate the value of the median rate of this contribution for these specific pensions.
To determine the median rate, we need to consider the specific values mentioned:
6.8 points for a rate of 3.8% or 6.2% 4.2 points for a rate of 6.6% 5.9 points for a rate of 8.3%No specific rate is directly attributed to retirement and disability pensions in the text. Therefore, it is impossible to determine the median rate of the deductible CSG on these retirement and disability pensions solely based on the information provided in this text.
We see here all the difficulty of the task: The model’s response contains the answer, but the way the law article is written does not allow it to be determined with certainty. Indeed, the median rate is not directly indicated in the text, it must be deduced from the rate information.
We can help the model by providing the previous value since we know it, by adding the following sentence: Knowing that the previous value was ‘0.042’
Now the answer is correct:
{
"value": 0.042
}But this is not a reliable solution because if we change the example value to ‘0.040’, it doesn’t succeed. So there are cases where even when giving the law text, it is not possible to get a reliable answer. However, cases that may seem complex for a human are handled satisfactorily. This is the case for long texts with many figures, or even double-entry tables, which are seen as text in this form by the model:
<p>Les plafonds de loyers visés au 2° de l'article D. 823-16 du même code sont fixés comme suit (en euros) :</p><p></p><center><div class="table-responsive"><table border="1"><tbody><tr><th><br>
Zone</th><th><br>
Personne seule</th><th><br>
Couple sans personne à charge</th><th><br>
Personne seule ou couple<br><p> <br>
ayant une personne à charge</p></th><th><br>
Par personne à charge<br><p> <br>
supplémentaire</p></th></tr><tr><td align="center"><br>
I</td><td align="center"><br>
319,30</td><td align="center"><br>
385,09</td><td align="center"><br>
435,24</td><td align="center"><br>
63,15</td></tr><tr><td align="center"><br>
II</td><td align="center"><br>
278,28</td><td align="center"><br>
340,62</td><td align="center"><br>
383,28</td><td align="center"><br>
55,79</td></tr><tr><td align="center"><br>
III</td><td align="center"><br>
260,82</td><td align="center"><br>
316,17</td><td align="center"><br>
354,51</td><td align="center"><br>
50,81</td></tr></tbody></table></div></center><p></p><p><br></p><p> </p><p></p>Which gives the following table:
Zone |
Personne seule |
Couple sans personne à charge |
|
|
|---|---|---|---|---|
I |
319,30 |
385,09 |
435,24 |
63,15 |
II |
278,28 |
340,62 |
383,28 |
55,79 |
III |
260,82 |
316,17 |
354,51 |
50,81 |
The answer to the question What is the value of “Rent ceiling taken into account in the calculation of housing benefits for a couple without dependents in zone 1 (after the 2001 reform)”? is correctly given by the model: 385.09. To achieve this result, we need to be able to provide the LégiFrance text. However, the reference indicated in OpenFisca may only concern the value already present. This is not what interests us. We have created a Python library exploiting the database of Tricoteuses which is a formatting of the open data from DILA, which serves as the basis for LégiFrance.
Thus, starting from the link present in OpenFisca, we can retrieve the different versions of a text, its application date, modifying decrees, etc…
The entire project therefore does not rely on LLMs, it was necessary to provide substantial work to set up the tools necessary for the exploitation of LLMs. Both to prepare the texts and to manipulate OpenFisca parameters in order to update them.
A library has also been created to create the description of a parameter from its tree structure by asking an LLM to reformulate it. Another call to a model is made to find the application date from the DILA note, which may be different from the publication date of the text or decree.
However, when the reference does not exist, it becomes complex. We then opted for an agent approach which consists of creating tools that we make available to an LLM for it to use. In reality, it will ask us to use them for it and send back the result. Then it will decide on the next step to follow. For example, we allow it to perform a web search, then read the content of a page.
Thus, it will be able to browse the web in search of the missing reference. This process has proven effective. Here is an example of improving an existing parameter by this system, additions are in green:
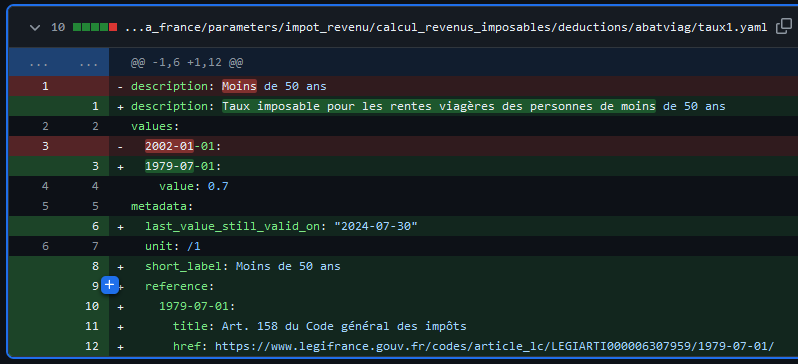
Source : PR #2332
We will now detail these two approaches that we have used.
Guided LLM
This approach consists of guiding the model by providing additional information to help it respond correctly. Therefore, we must start by retrieving the law article indicated in the OpenFisca parameter.
We can start from the complete aggregated list of parameters, raw_processed_parameters.json for mass updating. Or from a specific parameter file, such as marche_travail.salaire_minimum.smic.smic_b_horaire.
The openfisca_param.py library was developed to facilitate this task.
Then we created a LegiDB library that exploits the Tricoteuses database, which is a formatting of DILA’s open data, which publishes LégiFrance. This is an important step because we need to make the best use of this data to obtain the relevant text.
By combining this information in a prompt, as seen in the previous chapter, we manage to get correct answers in most cases.
We then need to update the parameter file in the OpenFisca-france source with the obtained response. Then an update request is made to the OpenFisca community for the modification to be integrated into the next version, after validation. So there is always human validation of the relevance of the modification.
Here is a summary diagram of this approach:
Intelligent Agents Approach (Autonomous LLM)
As seen in the first chapter, this approach gives more freedom to the LLM, which can request actions to be performed. This allows for handling more complex cases, such as searching for a missing reference.
A reformulation of the parameter description is done as a first step because OpenFisca parameter descriptions are not always explicit for parameters that have no references: these are parameters less frequently manipulated by the community. This reformulation is done by an LLM based on the description tree. The goal is to have a self-contained description and a short_label that is used in the LexImpact web interface. For example, for The taxation of life annuities, the old description was Less than 50 years old, the LLM reformulated it as Taxable rate for life annuities of people under 50 years old and added a short label Under 50 years old.
For the agent to be able to perform actions, it must be provided with tools. We have added tools like Google Search or Tavily, a search engine optimized for LLMs, and the ability to retrieve the content of a web page. These tools are made available to the LLM which can use them to perform actions. For example, it can ask Google to search for a missing legal reference, then read the content of a web page that is part of the result.
The LLM can also ask another LLM to verify the answer it has obtained. This allows for validating the obtained answer.
It can perform these steps in the order it wishes and as many times as it wishes. However, there is a limit to the number of calls to avoid going in circles for nothing. And a keyword that the LLM must use to indicate that it has finished.
The agents are in fact only instances of simple LLMs as in the previous chapter, but which have the ability to request actions to be performed.
To organize these calls, we use the Python library LangGraph which allows describing decision processes. Here is the summary diagram of this approach:
graph TD
E(OpenFisca parameter) --> F[Reformulates the description<br/> with an LLM]
F --> |Description| B[Builds the prompt]
B --> Lawer_reference_specialist
Lawer_reference_specialist["Researcher Agent"] --> Lawer_checker["Checker Agent"]
subgraph "Preparation"
E
F
B
end
subgraph "LLM Agents                                                   "
Lawer_reference_specialist
Lawer_checker
end
Lawer_checker --> fin["Final answer"]
Lawer_checker --> call_tool["Tools"]
Lawer_reference_specialist --> call_tool
Lawer_checker --> Lawer_reference_specialist
call_tool --> Lawer_checker
call_tool --> Lawer_reference_specialist
Google["Web search"] --> call_tool
WebCrawler["Web page retriever"] --> call_tool
subgraph "Available tools"
call_tool
Google
WebCrawler
end
fin --> D[Updates the parameter]
D --> G{Human review}
G --> |yes|I[Updates OpenFisca-France]
G --> |no|H[Rejected]
subgraph "Finalization"
fin
D
G
I
H
end
Recurring Costs
Using models hosted by private companies like OpenAI and accessible through APIs greatly facilitates things but incurs expenses as each API call must be paid for; there is no free offer like with public web versions.
Prices vary greatly depending on the model used, even from the same provider, here OpenAI, as of September 3, 2024:
| Model | Cost / 1M input tokens |
|---|---|
| gpt-4 | $30.00 |
| gpt-4o-2024-08-06 | $2.50 |
| gpt-4o-mini-2024-07-18 | $0.150 |
Source: OpenAI API Pricing Here is an excerpt of amounts billed for our usage:
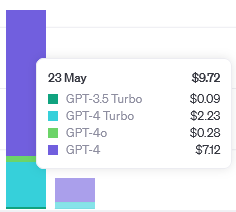
On May 23, 2024, our GPT-4 tests had cost $7 for 215 calls, or 3.2 cents per call. While 63 calls to GPT-4o-mini on July 23, 2024, cost 3 cents, or 0.05 cents per call, a reduction by a factor of 64 !
If we consider that we need to make 2,000 calls per month to keep the parameters up to date, this represents a monthly cost of $100 for GPT-4o-mini.
Future Directions
- Integration into the OpenFisca workflow is ongoing. The initial objective of the project envisioned automatic mass updating, however, the need for human review suggests that it would be preferable to have a web interface for requesting targeted updates, which would then be validated by the community.
- Cost and sovereignty concerns arise, hence the need to explore open-source LLM alternatives, such as Llama 3 or Mistral models.
In this context, Jean-Zay resources were used to train open models. The fine-tuning source code is available on the LexImpact GitLab.
However, this part was put on hold to focus on integration into work processes in order to validate feasibility across the entire chain. For this, we used the OpenAI API which allowed for superior results to the open models available in 2023.
Now that we have validated the project’s feasibility, we wish to resume this work in 2025 to be able to use open models, whose performance continues to improve.
Conclusion
The experience demonstrates the potential of LLMs in automating complex legal and administrative tasks. Although challenges remain, the rapid progress in LLM capabilities suggests a promising future for AI-assisted maintenance of systems like OpenFisca.
The project has shown significant progress over the past year, with a success rate from unusable at the beginning of the project to over 90% today, showing the speed at which the technology is evolving. It is therefore important to maintain constant vigilance on advancements both in terms of models and tools to exploit them.
In the very long term, it could be envisaged to maintain in this way not only the fiscal parameters but also the translation of texts into Python code.
Acknowledgments
- This work benefited from access to IDRIS computing resources through the allocation of resources 2023-AD011014553 granted by GENCI. We had access to the Jean Zay supercomputer to fine-tune existing models and evaluate large OpenSource models like Llama.
- Participation in Etalab’s 10% program allowed us to benefit from the group’s emulation around these technologies.