Automatiser le processus Rules as Code avec l’IA : retours d’expérience de LexImpact
Par Benoît Courty, équipe LexImpact, Assemblée nationale
English version: Automating the Rules as Code Process with AI: Lessons from LexImpact.
Cet article de blog est basé sur une présentation donnée à Rules as Code Europe 2026 à La Haye.
Les diapositives sont disponibles.
Rules as Code est souvent présenté comme un pur défi de modélisation : encodez correctement les règles juridiques, et le problème est résolu. En pratique, la partie la plus difficile arrive après la première implémentation : maintenir le modèle aligné avec les évolutions législatives mois après mois, sur des milliers de paramètres.
Chez LexImpact, notre mission principale est de construire et maintenir des outils utilisés dans le travail parlementaire réel pour estimer l’impact fiscal des amendements législatifs. Cela signifie que la fiabilité, la traçabilité et la capacité de contrôle ne sont pas optionnelles. Elles font partie de l’exigence démocratique.
Parallèlement à ce travail principal, nous menons un projet de recherche exploratoire depuis 2023 pour déterminer si l’IA pourrait aider sur l’un de nos points de douleur récurrents : maintenir à jour des milliers de paramètres fiscaux. Cet article partage ce que nous avons appris en chemin — des faibles résultats initiaux des LLM à des flux de travail plus pratiques assistés par l’IA, et maintenant des premières expérimentations de génération de code juridique directement à partir du texte de loi.

Pourquoi c’est important pour le travail parlementaire
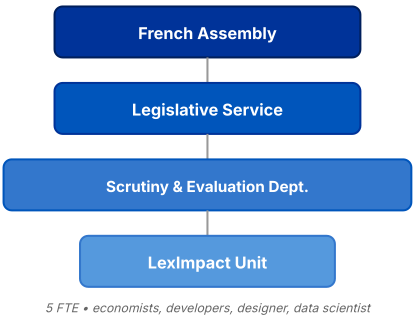
LexImpact opère au sein de l’Assemblée nationale française, dans le cadre de l’article 24 de la Constitution française :
Le Parlement vote la loi. Il contrôle l’action du Gouvernement. Il évalue les politiques publiques.
Pour soutenir cette mission, nous nous appuyons sur :
- OpenFisca-France, le modèle de microsimulation open source encodant les règles fiscales et sociales ;
- Des simulateurs en ligne, utilisés par les parlementaires et les parties prenantes publiques ;
- L’Open Data, pour accéder au droit publié par Légifrance, que nous utilisons à travers le projet Tricoteuses.
Rules as Code n’est pas seulement un travail juridique ou logiciel — cela fonctionne mieux quand différentes compétences collaborent. Notre petite équipe est composée d’environ cinq équivalents temps plein, réunissant des profils variés : économistes, développeurs, designer et data scientists.
L’interface peut sembler simple pour les utilisateurs finaux, mais chaque résultat dépend d’une longue chaîne de valeurs et de références juridiques en coulisses.
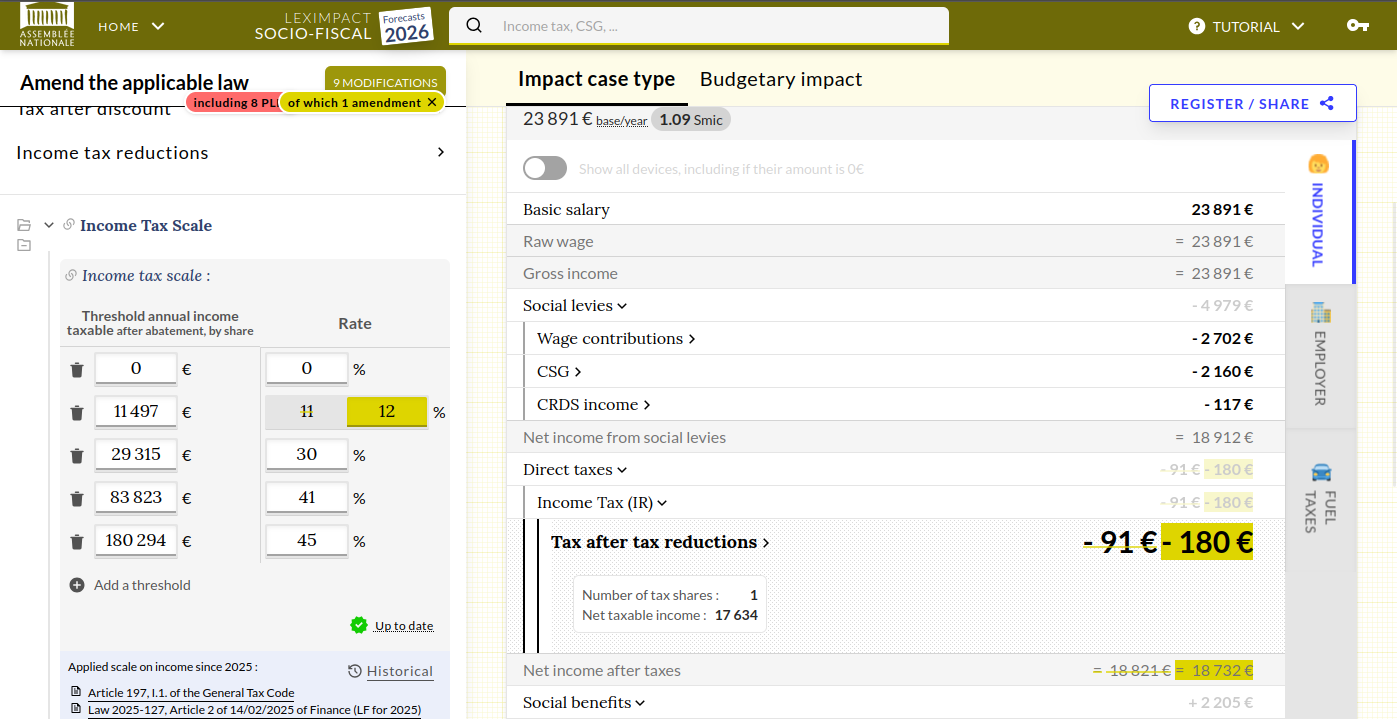
Le problème des paramètres à grande échelle
Dans OpenFisca, un paramètre n’est pas simplement un nombre. Il combine :
- une description ;
- une valeur (taux, seuil, plafond, tranche) ;
- des références juridiques ;
- et une date de dernière révision.
Cette structure est essentielle pour la confiance et la reproductibilité — mais elle crée aussi une lourde charge de maintenance. Pour les seuls impôts et prestations sociales des ménages français, nous suivons plus de 2 000 paramètres.
Voici comment ils s’affichent sur notre simulateur en ligne :
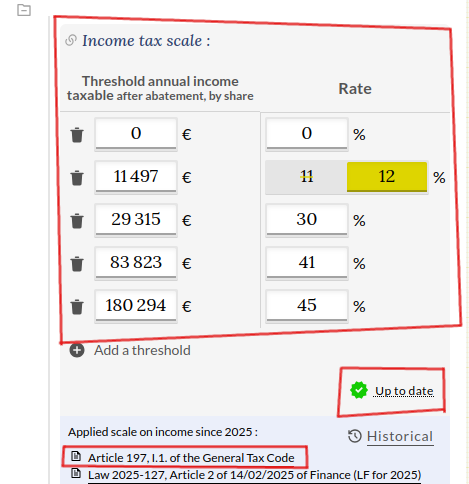
Les paramètres sont stockés au format YAML pour être lisibles par les machines et faciles à écrire par les humains :
description: Percentage of the reference daily wage (SJR) for the basic unemployment insurance allowance
values:
2020-10-01:
- value: 0.50
2025-10-01:
- value: 0.57
metadata:
last_review: "2025-09-01"
references:
2020-10-01:
- title: "Art. 197 of the Code..."
href: "https://www.legifrance.gouv.fr/codes/article_lc/LEGIARTI000006302473/"Les mises à jour manuelles ne passent pas à l’échelle. Le risque n’est pas seulement de manquer une réforme majeure, mais d’accumuler de petites dérives annuelles qui dégradent progressivement la qualité du modèle.
C’est pourquoi nous avons décidé d’expérimenter un système d’IA pour aider à les mettre à jour.
De 5 % à des flux de travail de qualité production
Nos premiers essais en 2023 étaient médiocres (environ 5 % de réussite sur les tâches d’extraction qui nous intéressaient). Le tournant est venu de deux effets combinés :
- De meilleurs modèles avec des fenêtres de contexte beaucoup plus grandes (passant de 4 000 tokens en 2023 à plus de 1 million de tokens en 2026) ;
- Une meilleure conception des flux de travail autour de la recherche, du prompting et de la revue humaine.
La taille de la fenêtre de contexte a changé la faisabilité
En 2023, les modèles d’IA étaient limités à environ 4 000 tokens. C’était souvent insuffisant une fois incluses les instructions, les fichiers de paramètres et les sources juridiques (par exemple, l’article 199 undecies B à lui seul fait 8 922 tokens). En 2026, les modèles à grand contexte ont rendu de nombreux cas autrefois impossibles traitables, permettant 1 million de tokens en entrée.
Un token représente environ 4 caractères :

Les tokens d’entrée sont remplis par :
- le texte de loi,
- le fichier de paramètres précédent,
- les instructions du prompt, …
Les modèles de 2023 ne pouvaient donc pas traiter certains textes de loi.
L’évaluation est devenue indispensable
Nous avons construit un jeu de données de benchmark (165 paramètres avec des valeurs attendues et des références connues) et comparé les modèles sur les mêmes tâches et prompts. Cela nous a aidés à éviter le biais de démonstration et à suivre les progrès pratiques au fil du temps. Les résultats sont disponibles sur git.leximpact.dev/leximpact/exploration/fiscal-qa.
Sur les modèles testés, les taux de réussite ont atteint des performances intéressantes :
DeepSeek-R1 : 90 % à 99 % de réussite (plus lent, 1h43 minutes pour le jeu de données)
GPT-4 / GPT-5.4 : ~86-93 % de réussite
Llama-3.3-70B : ~91,5 % de réussite, très surprenant vu la petite taille de ce modèle.
Ministral Large/Medium : 85-86 % de réussite (beaucoup plus rapide, 4,5 minutes, coût très faible à ~0,39 € pour 165 paramètres)
Le point principal ici n’est pas l’origine du modèle, mais que la qualité des modèles peut changer très vite. Un flux de travail qui ne fonctionnait pas une année peut devenir performant l’année suivante. C’est pourquoi l’évaluation continue est importante, et pourquoi nous essayons de rester agnostiques vis-à-vis des modèles pour pouvoir en changer facilement quand nécessaire. Il faut aussi garder à l’esprit que les modèles d’IA générative ne sont pas déterministes, donc les résultats peuvent varier entre les exécutions avec la même demande en entrée. De plus, nous utilisons strictement le même prompt depuis 2023 pour le benchmark, or le prompt que nous utilisons aujourd’hui a changé, et le meilleur prompt varie selon les modèles. Il faut donc prendre les résultats du benchmark avec beaucoup de précaution.
Le virage clé : de l’« automatisation totale » à l’« automatisation centrée sur la revue »
Notre idée initiale était une mise à jour mensuelle en lots de tous les paramètres. Cependant, le processus est plus nuancé :
- certains paramètres n’ont pas de références ;
- certaines références sont obsolètes ou incorrectes ;
- certaines sources juridiques sont en dehors de Légifrance ;
- et les sorties de l’IA nécessitent encore des ajustements éditoriaux/juridiques.
La décision produit la plus importante a été d’optimiser pour des boucles de revue humaine, et non pour une automatisation de bout en bout aveugle.
Ce virage a eu une conséquence directe sur l’outillage. Si la qualité de la revue compte, alors l’expérience de revue compte aussi.
Pourquoi l’interface desktop a amélioré la qualité
Nous avons d’abord construit une interface web ; une application de bureau s’est révélée meilleure pour les mainteneurs :
- accès direct aux dépôts OpenFisca locaux ;
- inspection immédiate des diffs dans VS Code ;
- modifications faciles avant commit ;
- intégration transparente avec les flux de travail de revue git habituels.
Cela a augmenté l’adoption pratique car l’étape IA s’insère naturellement dans les habitudes de travails existantes.
Structure du prompt
Le prompt combine la définition actuelle du paramètre (valeur, références, date de révision) avec le texte juridique pertinent récupéré depuis Légifrance. Le modèle est invité à raisonner sur la validité actuelle de la valeur et, si nécessaire, à proposer une mise à jour avec la source et la date. Garder le prompt explicite sur les informations disponibles — et sur ce que le modèle ne doit pas inventer — est essentiel pour réduire les hallucinations.
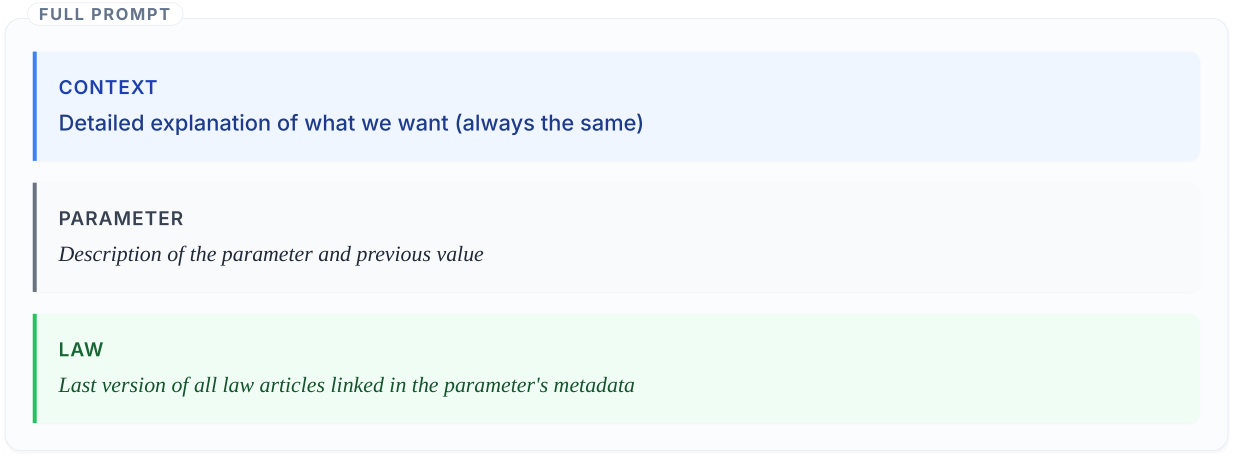
Flux de travail pour les paramètres avec références
Pour les paramètres qui incluent déjà des références juridiques, le flux de travail est désormais bien structuré :
- extraire les paramètres avec avertissement de péremption dans notre interface simulateur ;
- récupérer le dernier texte de loi via des outils MCP connectés à des sources juridiques de confiance (un serveur MCP fournit simplement un moyen pour le modèle d’utiliser des outils et données de confiance, au lieu de deviner à partir de ce dont il se souvient de son apprentissage initial) ;
- construire le prompt avec le paramètre actuel + le contexte juridique ;
- demander au modèle si la valeur est toujours valide ou nécessite une mise à jour ;
- réécrire la valeur/référence/date de révision ;
- demander une revue humaine avant acceptation.
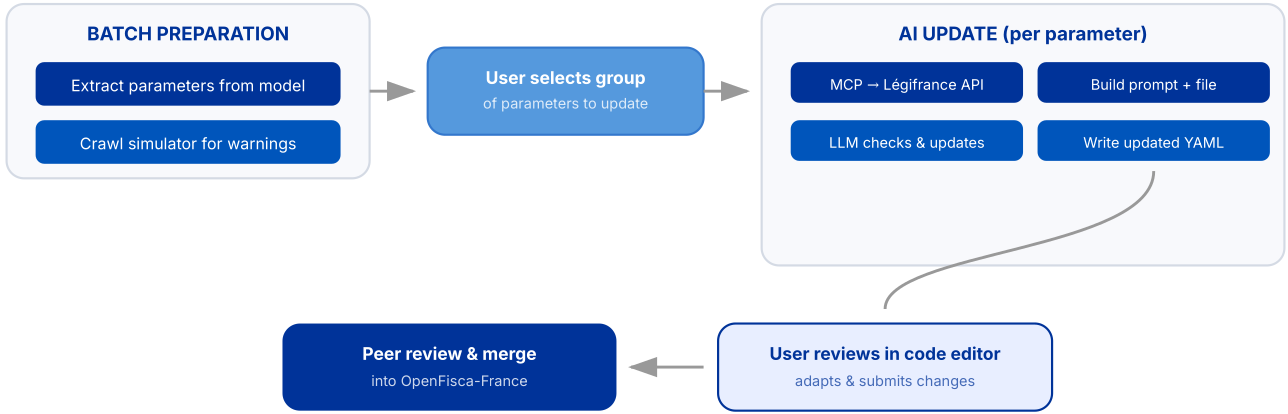
Ce flux de travail gère bien le cas courant. L’utilisation en conditions réelles fait émerger de nombreuses situations qui ne correspondent pas parfaitement à ce scénario idéal.
Les cas d’échecs
Une veille juridique assistée par l’IA fiable nécessite un traitement explicite des échecs courants :
- langage juridique ambigu ;
- sources en dehors des bases de données juridiques officielles ;
- hallucinations du modèle ;
- références juridiques erronées ;
Traiter ces cas comme des cas de première importance (plutôt que comme des cas marginaux) est ce qui rend le flux de travail robuste.
Il y a deux échecs que nous ne pouvons pas éviter avec cette première solution :
- les références manquantes ;
- les décrets obsolètes remplacés par de nouvelles publications sans lien avec celle d’origine ;
Pour ceux-ci, nous avons construit un procédé agentique.
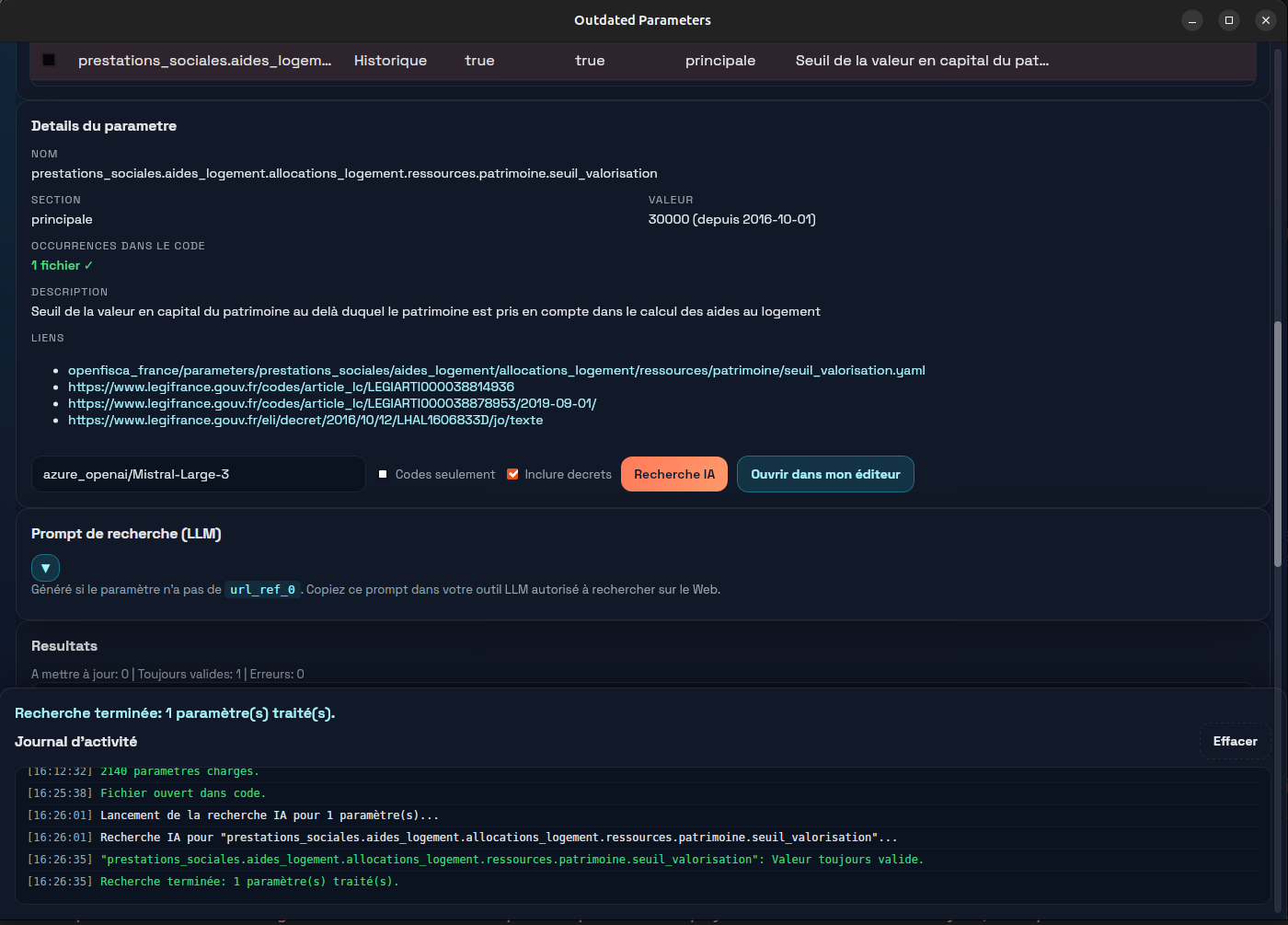
Références manquantes : recherche et vérification agentiques
Quand aucune référence fiable n’existe, l’extraction ne peut pas commencer directement. Nous avons ajouté un flux agentique pour séparer :
- la découverte de sources,
- la vérification des sources,
- et la proposition de valeur finale.
Cette décomposition permet de fournir des premières réponses fiables et améliore la traçabilité.
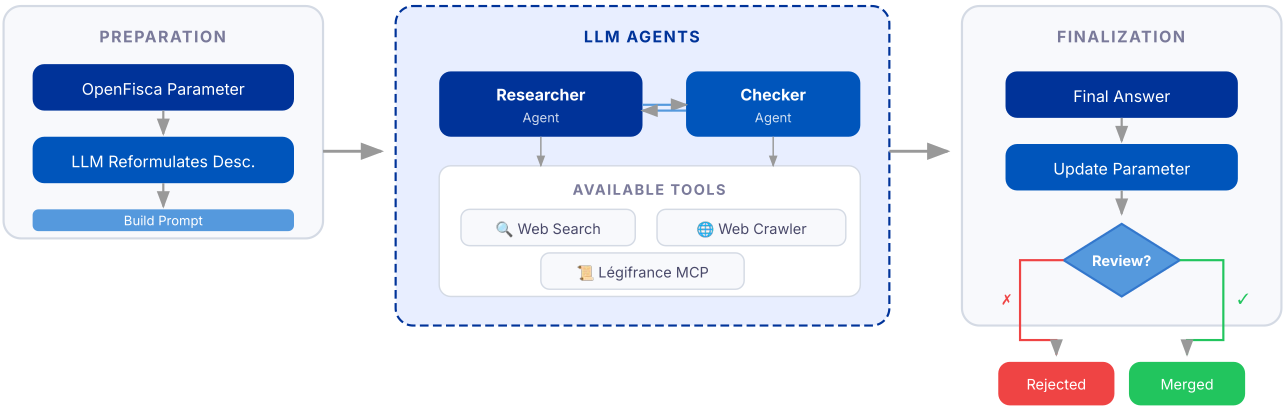
Gérer à la fois les cas référencés et non référencés amène la maintenance des paramètres à un niveau opérationnellement réaliste pour une équipe du secteur public. Une fois cette base en place, une question naturelle s’est posée : si l’IA peut mettre à jour les paramètres de manière fiable, peut-elle aussi aider pour des changements juridiques plus larges et structurels ?
Plus récemment, les flux de travail basés sur des « skills » ont facilité l’opérationnalisation de certaines de ces tâches. Au lieu de construire un flux de travail agentique complet et personnalisé, nous pouvons donner au modèle des instructions réutilisables et un accès au code source local. Cela aide le modèle à mieux comprendre le projet OpenFisca et rend les flux de travail plus faciles à construire, en particulier pour les experts métier qui n’ont pas toujours besoin d’un développeur pour créer un flux complexe.
Un autre exemple très intéressant de modélisation rapide de politiques publiques assistée par l’IA utilisant des concepts similaires est ce que Policy Engine a construit pour les politiques britanniques et américaines.
Perspectives 2026 : du texte juridique au code exécutable
Au-delà des mises à jour de paramètres, nous testons maintenant la génération directe de code à partir de textes législatifs : d’un projet de loi de finances à une implémentation OpenFisca. Les premiers résultats montrent que des premières ébauches en une passe peuvent déjà faire gagner un temps substantiel, y compris pour certaines modifications non triviales.
Le bon cadrage n’est pas le codage autonome du droit. Le bon cadrage est des premières ébauches plus rapides et de meilleure qualité en gardant l’humain au coeur du processus.
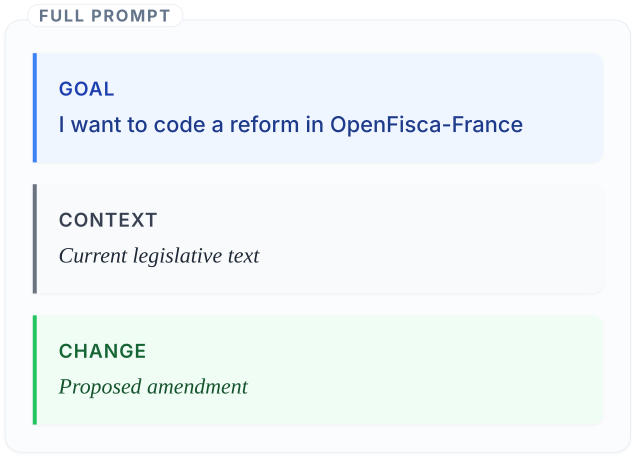
Tous ces flux de travail — qu’ils soient pour la mise à jour de paramètres ou la génération de code — ne sont viables que si les institutions peuvent effectivement se les permettre et garder le contrôle sur leur fonctionnement.
Souveraineté et coût : contraintes pratiques dans les institutions publiques
Le travail avec l’IA dans le secteur public comporte des contraintes supplémentaires :
- besoin de transparence et de contrôle ;
- préférence pour les écosystèmes open source/open weight quand c’est faisable ;
- architecture agnostique vis-à-vis des modèles pour éviter le verrouillage.
Économiquement, les très grands déploiements on-premise de modèles open weight peuvent être coûteux (matériel + opérations). Par exemple, héberger Mistral-Large-3-Instruct FP8 nécessite un serveur avec 8 cartes NVIDIA H200, pour un total d’environ 300 000 €. Alternativement, des ressources de calcul gratuites pour les institutions publiques de l’Europe existent via EuroHPC, mais restent limitées à l’entraînement et à l’inférence par lots.
L’utilisation par API est souvent plus réaliste pour des flux de travail ciblés. Le paiement à l’usage via des fournisseurs cloud ou des plateformes peut être très bon marché (ex. : Ministral 3 à 20 centime par million de tokens). Selon nos estimations, la mise à jour d’environ 2 000 paramètres avec des modèles modernes peut rester en dessous de 100 €/mois, tout en nécessitant une attention à la croissance de l’usage des tokens par les pipelines agentiques de plus en plus complexes.
Les impacts environnementaux doivent aussi être mesurés et pris en compte à l’aide d’outils comme CodeCarbon ou EcoLogits.
Principaux enseignements
- L’IA est puissante mais pas magique : l’ingénierie, l’ancrage juridique et l’évaluation restent les moteurs de la qualité. Sans un benchmark solide, une chaîne de recherche bien conçue et une discipline de revue, l’assistance par IA produit du bruit, pas des gains de productivité.
- Le changement d’échelle : la maintenance de paramètres à grande échelle est désormais opérationnellement réaliste. Ce qui semblait hors de portée en 2023 est, en 2026, un flux de travail utilisable par une petite équipe.
- Le flux de travail compte autant que la qualité du modèle : les interfaces, l’outillage de recherche et les pratiques de revue sont déterminants.
- L’humain est indispensable : la confiance dépend d’une discipline de revue soutenue. En fait, cela pourrait devenir plus difficile à l’avenir : si les modèles font moins d’erreurs, les relecteurs peuvent naturellement prêter moins d’attention. Maintenir une culture de vérification forte est l’un des plus grands défis à venir.
- La souveraineté et le coût sont des contraintes de conception, pas des considérations secondaires : les institutions publiques ne peuvent pas simplement adopter le modèle qui performe le mieux dans un comparatif. La transparence, la prévisibilité des coûts, les alternatives ouvertes et l’impact environnemental façonnent les décisions.
Pour une démarche Rules as Code dans les services publics, la promesse la plus utile de l’IA aujourd’hui est de permettre à de petites équipes de construire des outils utiles pour les agents publics et les citoyens. Il s’agit de réduire suffisamment les coûts de maintenance pour garder les modèles juridiques à jour, transparents et utiles à l’échelle institutionnelle.
Cette réduction des coûts a une importance qui va au-delà de l’efficacité. Quand la maintenance devient trop lourde, les équipes font des compromis, les références deviennent obsolètes, et le modèle perd silencieusement l’ancrage juridique qui le rend digne de confiance. Les flux de travail assistés par l’IA ne font pas que gagner du temps — ils aident à préserver l’intégrité épistémique du modèle lui-même.
À l’avenir, la frontière entre la maintenance des paramètres et la génération de code commence à s’estomper. À mesure que les modèles s’améliorent et que les flux de travail mûrissent, une plus grande partie du travail d’encodage routinier pourrait devenir un territoire de premières ébauches automatisables, déplaçant le rôle des experts juridico-techniques vers la revue, la validation et les questions interprétatives plus difficiles que l’IA est encore loin de bien traiter. Le défi pour les institutions sera de développer cette capacité de revue intentionnellement, plutôt que de la laisser s’éroder proportionnellement à la rareté des erreurs du modèle.
Projet source : https://git.leximpact.dev/leximpact/exploration/update-openfisca-with-ai