Automating the Rules as Code Process with AI: Lessons from LexImpact
By Benoît Courty, LexImpact team, French National Assembly
Version française : Automatiser le processus Rules as Code avec l’IA : retours d’expérience de LexImpact.
This blog post is based on a talk I gave at Rules as Code Europe 2026 in Den Hague.
The slides are available.
Rules as Code is often presented as a pure modeling challenge: encode legal rules correctly, and the problem is solved. In practice, the hardest part comes after the first implementation: keeping the model aligned with legal changes month after month, across thousands of parameters.
At LexImpact, our core mission is building and maintaining tools used in real parliamentary work to estimate the fiscal impact of legislative amendments. That means reliability, traceability, and reviewability are not optional. They are part of the democratic requirement.
Alongside that main work, we have been running a side research project since 2023 to explore whether AI could help with one of our recurring pain points: keeping thousands of fiscal parameters up to date. This article shares what we learned along the way—from weak early LLM results to more practical AI-assisted workflows, and now early experiments in generating legal code directly from bill text.

Why this matters for parliamentary work
LexImpact operates inside the French National Assembly, in the context of Article 24 of the French Constitution:
The Parliament shall pass statutes. It shall monitor the action of the Government. It shall assess public policies.
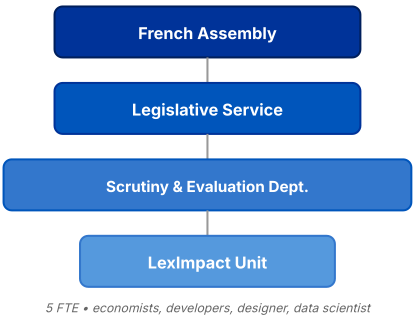
To support this mission, we rely on:
- OpenFisca-France, the open-source microsimulation model encoding tax and benefit rules;
- Online simulators, used by parliamentarians and public stakeholders;
- Open Data, to access law published by Légifrance, which we used through theTricoteuses project.
Rules as Code is not merely a legal or software job—it works best when different skills work together. Our small team consists of about five full-time equivalents, drawing on a mix of profiles: economists, developers, a designer, and data scientists.
The interface may look simple for end users, but each output depends on a long chain of legal values and references behind the scenes.
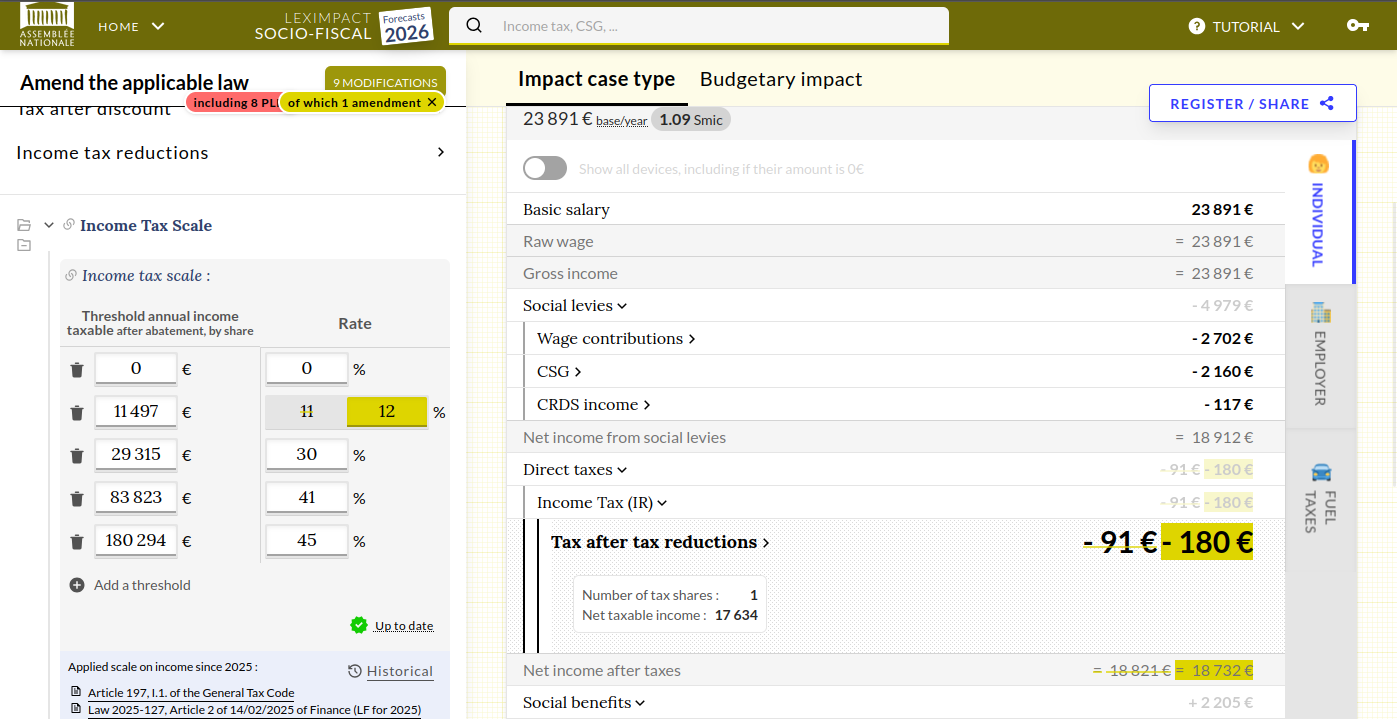
The parameter problem at scale
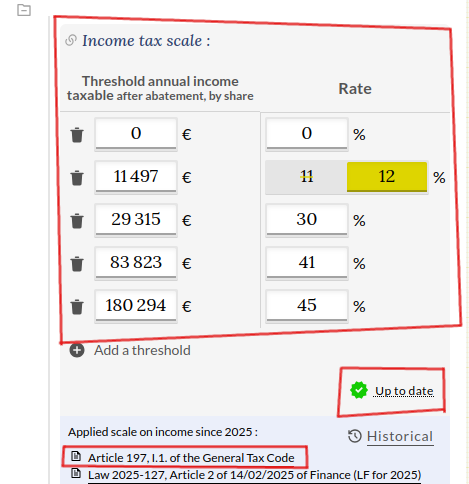
In OpenFisca, a parameter is not just a number. It combines:
- a description
- a value (rate, threshold, ceiling, bracket);
- legal references;
- and a last review date.
That structure is essential for trust and reproducibility—but it also creates a heavy maintenance burden. For French household tax and social benefits alone, we monitor more than 2,000 parameters.
Here is how it is displayed on our online simulator:
Parameters are stored in YAML format to be machine readable and easy to write by human:
description: Percentage of the reference daily wage (SJR) for the basic unemployment insurance allowance
values:
2020-10-01:
- value: 0.50
2025-10-01:
- value: 0.57
metadata:
last_review: "2025-09-01"
references:
2020-10-01:
- title: "Art. 197 of the Code..."
href: "https://www.legifrance.gouv.fr/codes/article_lc/LEGIARTI000006302473/"Manual updates do not scale well. The risk is not only missing one major reform, but accumulating small yearly drifts that progressively degrade model quality.
That’s why we decide to experiment an AI system to help update them.
From 5% to production-grade workflows
Our first trials in 2023 were poor (around 5% success on the extraction tasks we cared about). The turning point came from two combined effects:
- Better models with much larger context windows (moving from 4K tokens in 2023 to 1M+ tokens in 2026);
- Better workflow design around retrieval, prompting, and human review.
Context window size changed feasibility
In 2023, AI models were limited to roughly 4K tokens. That was often insufficient once you include instructions, parameter files, and long legal sources (for example, Article 199 undecies B alone is 8,922 tokens). By 2026, large-context models made many previously impossible cases tractable, allowing 1 million tokens input.
A token is roughly 4 characters:

The input tokens are filled with:
the law text,
the previous parameter file,
the prompt instructions, …
So the 2023 models could not handle some law text.
Evaluation became mandatory
We built a benchmark dataset (165 parameters with known expected values and references) and compared models on the same tasks and prompts. This helped us avoid demo bias and track practical progress over time. The results are available at git.leximpact.dev/leximpact/exploration/fiscal-qa.
Across tested models, success rates moved into highly useful ranges, with large differences in latency and cost:
DeepSeek-R1: 90% to 99% success (slower, ~1h43m for the dataset)
GPT-4 / GPT-5.4: ~86-93% success
Llama-3.3-70B: ~91.5% success, very surprising given the small size of this model.
Ministral Large/Medium: 85-86% success (much faster, ~4.5m, very low cost at ~0.39€ for 165 parameters)
The main point here is not the brand of the model, but that model quality can change very fast. A workflow that did not work one year can become practical the next. This is why continuous evaluation is important, and why we try to stay model-agnostic to easily switch models when needed. We also have to keep in mind that GenAI models are not deterministic, so results can vary between runs with the same input. Furthermore, we strictly use the same prompt since 2023 for the benchmark, but the prompt we use today has changed, and the best prompt varies between models. So take benchmark results very carefully.
The key shift: from “full automation” to “review-centered automation”
Our initial idea was a monthly batch update of all parameters. In reality, the process is more nuanced:
- some parameters lack references;
- some references are outdated or incorrect;
- some legal sources are outside Légifrance;
- and AI outputs still require editorial/legal adjustments.
The most important product decision was to optimize for human review loops, not for blind end-to-end automation.
That shift had a direct consequence on tooling. If review quality matters, then the review experience matters too.
Why desktop UI improved quality
We first built a web interface; a desktop application turned out to be better for maintainers:
- direct access to local OpenFisca repositories;
- immediate diff inspection in VS Code;
- easy pre-commit edits;
- seamless integration with normal git review workflows.
This increased practical adoption because the AI step fits naturally into existing engineering habits.
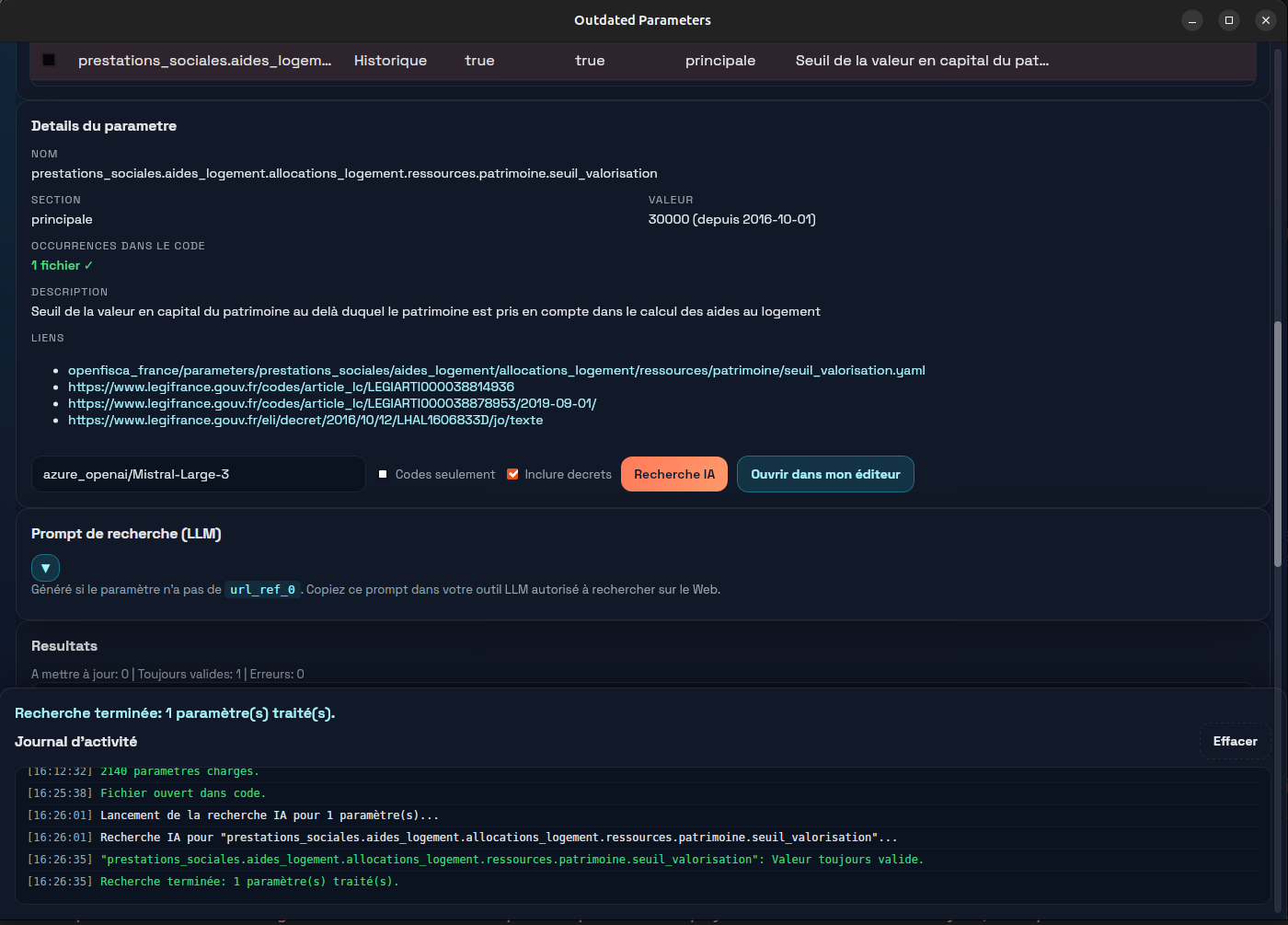
Prompt structure
The prompt combines the current parameter definition (value, references, review date) with the relevant legal text retrieved from Légifrance. The model is asked to reason about whether the value is still valid, and if not, to propose an update with source and date. Keeping the prompt explicit about what information is available — and what the model should not invent — is key to reducing hallucinations.
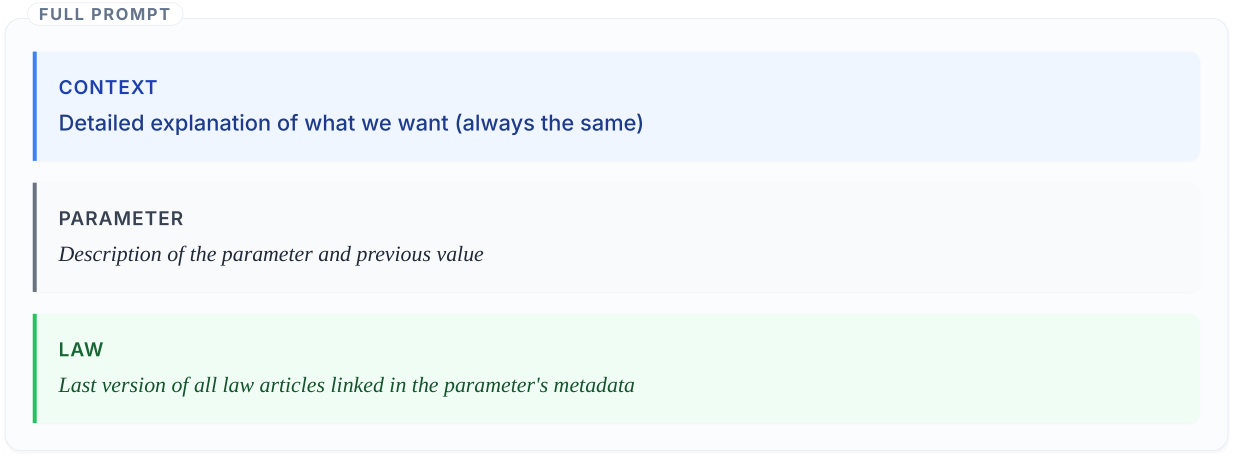
Workflow for parameters with references
For parameters that already include legal references, the workflow is now well-structured:
- extract the parameters with outdated warning in our simulator interface ;
- retrieve the latest legal text via MCP tools connected to trusted legal sources (an MCP server simply provides a way for the model to use trusted tools and data, instead of guessing from what it remembers);
- build prompt with current parameter + legal context;
- ask the model whether the value is still valid or needs an update;
- write back value/reference/review date;
- ask for human review before contribution and merge.
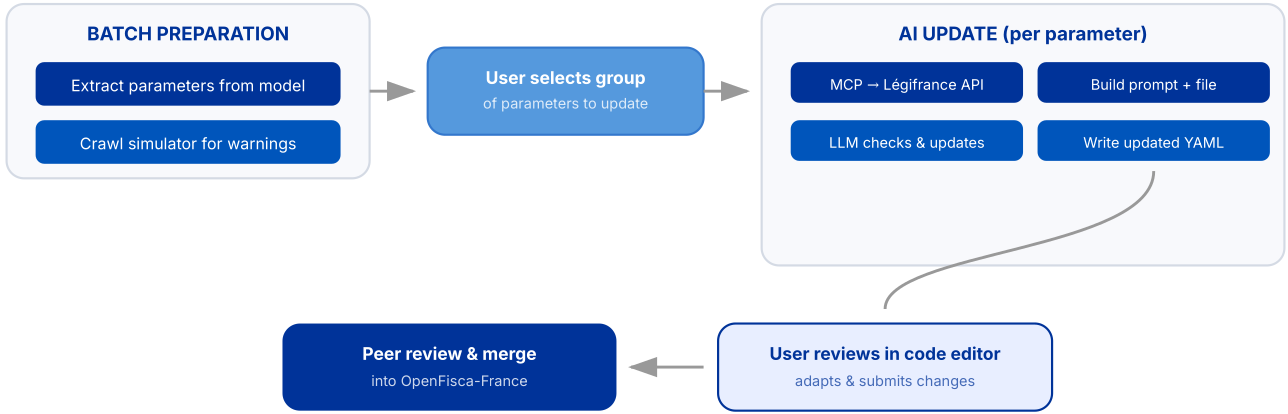
This workflow handles the common case well. But real-world maintenance surfaces many situations that don’t fit neatly into this happy path.
Failure modes are product requirements
Reliable AI-assisted legal maintenance requires explicit handling of common failures:
- ambiguous legal language;
- sources outside official legal databases;
- model hallucinations;
- wrong legal references;
Treating these as first-class cases (instead of edge cases) is what makes the workflow robust.
There is two failures that we can’t avoid with this first solution:
- missing references.
- outdated decrees replaced by new publications;
For them, we build an agentic pipeline.
Missing references: agentic search and checking
When no reliable reference exists, extraction cannot start directly. We added an agentic pipeline to separate:
- source discovery,
- source checking,
- and final value proposal.
This decomposition reduced acceptance of weak first answers and improved traceability.
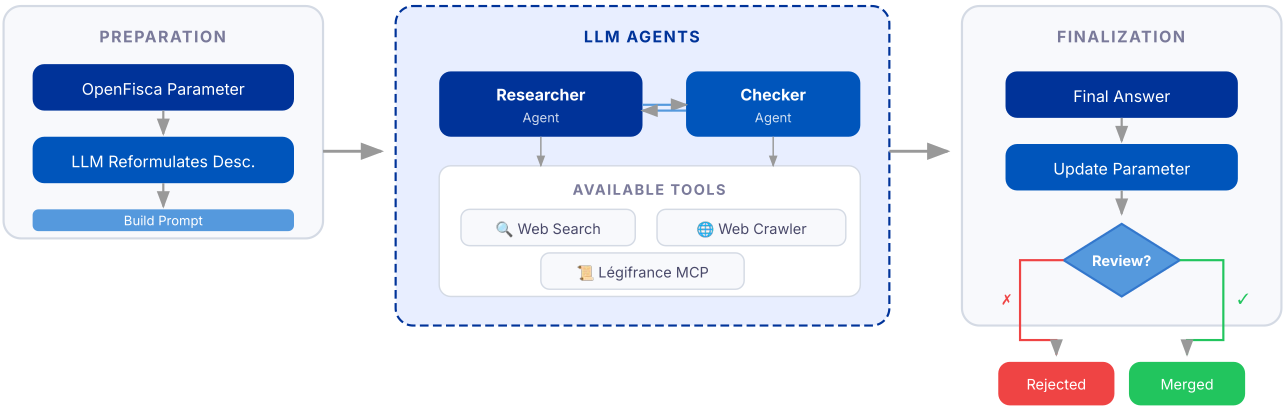
Handling both the referenced and the unreferenced cases brings parameter maintenance to a level that is operationally realistic for a public-sector team. Once that foundation was in place, a natural next question arose: if AI can update parameters reliably, can it also help with larger, structural legal changes?
More recently, “skills”-based workflows have made some of this easier to operationalize. Instead of building a full custom agent workflow, we can give the model reusable instructions and access to the local codebase. This helps the model better understand the OpenFisca project and makes workflows easier to build, especially for domain experts who do not always need a developer to create a complex pipeline.
Another very interesting example of fast AI-assisted policy modeling using similar concepts is what Policy Engine build for UK and US policies.
2026 frontier: from legal text to executable code
Beyond parameter updates, we now test direct code generation from legislative text (finance bill to OpenFisca implementation). Early results show that one-shot first drafts can already save substantial time, including for some non-trivial changes.
The right framing is not autonomous law coding. The right framing is faster, higher-quality first drafts for expert review.
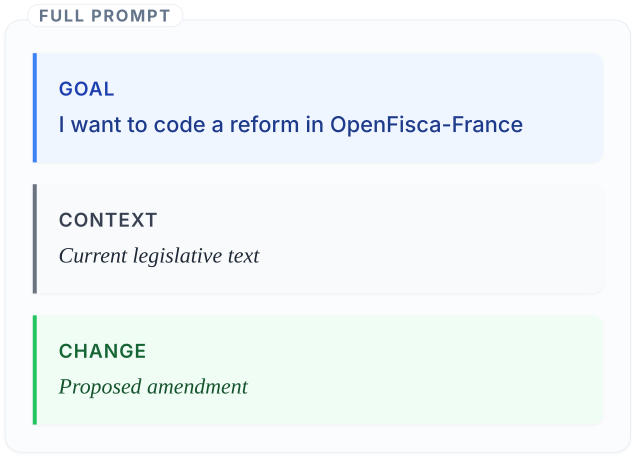
All of these workflows — whether for parameter updates or code generation — are only viable if institutions can actually afford to run them and retain control over how they operate.
Sovereignty and cost: practical constraints in public institutions
Public-sector AI work has additional constraints:
- need for transparency and control;
- preference for open-source/open-weight ecosystems when feasible;
- model-agnostic architecture to avoid lock-in.
Economically, very large on-prem open-weight deployments can be costly (hardware + operations). For instance, hosting Mistral-Large-3-Instruct FP8 requires a server with 8× NVIDIA H200 cards, costing around €300,000. Alternatively, free computational resources for EU public institutions exist via EuroHPC, but remain limited to training and batch inference.
API-based usage is often more realistic for targeted workflows. Pay-per-use through cloud providers or platforms can be very cheap (e.g., Ministral 3 at €0.20/1M tokens, Mistral Large 3 at €0.50/1M tokens). In our estimates, updating around 2,000 parameters with modern models can remain in an affordable range (around €100/month), while still requiring attention to token growth in agentic pipelines.
Environmental impacts should also be measured and factored in using tools like CodeCarbon or EcoLogits.
Main takeaways
- AI is powerful but not magical: engineering, legal grounding, and evaluation still drive quality. Without a solid benchmark, a well-designed retrieval chain, and discipline around review, AI assistance produces noise, not productivity gains.
- Scale changed: large parameter maintenance is now operationally realistic. What felt out of reach in 2023 is, by 2026, a tractable workflow for a small team.
- Workflow matters as much as model quality: interfaces, retrieval tooling, and review practices are decisive.
- Human-in-the-loop is non-negotiable: trust depends on sustained review discipline. In fact, this may become harder in the future: if models make fewer mistakes, reviewers may naturally pay less attention. Keeping a strong review culture is one of the biggest forward-looking challenges.
- Sovereignty and cost are design constraints, not afterthoughts: public institutions cannot simply adopt whatever model performs best in a benchmark. Transparency, cost predictability, open-weight alternatives, and environmental impact all shape which workflows are actually deployable.
For Rules as Code in public services, the most useful promise of AI today is to empower small team to build useful tool for public servant and citizens. It is reducing maintenance cost enough to keep legal models current, transparent, and useful at institutional scale.
That reduction in cost matters beyond efficiency. When maintenance becomes burdensome, teams cut corners, references go stale, and the model quietly loses the legal grounding that makes it trustworthy. AI-assisted workflows do not just save time — they help preserve the epistemic integrity of the model itself.
Looking forward, the boundary between parameter maintenance and code generation is starting to blur. As models improve and workflows mature, more of the routine encoding work may become automatable first-draft territory, shifting the role of legal-technical experts toward review, validation, and the harder interpretive questions that AI is still far from handling well. The challenge for institutions will be to develop that review capacity intentionally, rather than letting it erode in proportion to how rarely the model is wrong.
Source project: https://git.leximpact.dev/leximpact/exploration/update-openfisca-with-ai